 INGInious
INGIniousThis task will partially be graded after the deadline
- You will get a real-time feed-back for questions 1 to 3.
- They do not count for the final grade of the task, but you need to answer them correctly to answer the remaining questions (or else they will not be graded).
- Questions 4 to 15 will be graded after the deadline.
During the second assignment, you have seen that the XOR problem is not linearily separable in the input space. This problem however becomes separable when mapped to a new space using an appropriate kernel. An alternative way to tackle this problem is using a neural network. The goal of this task is to train such a network in order to solve the 2D XOR problem, defined by the following 4 data points:
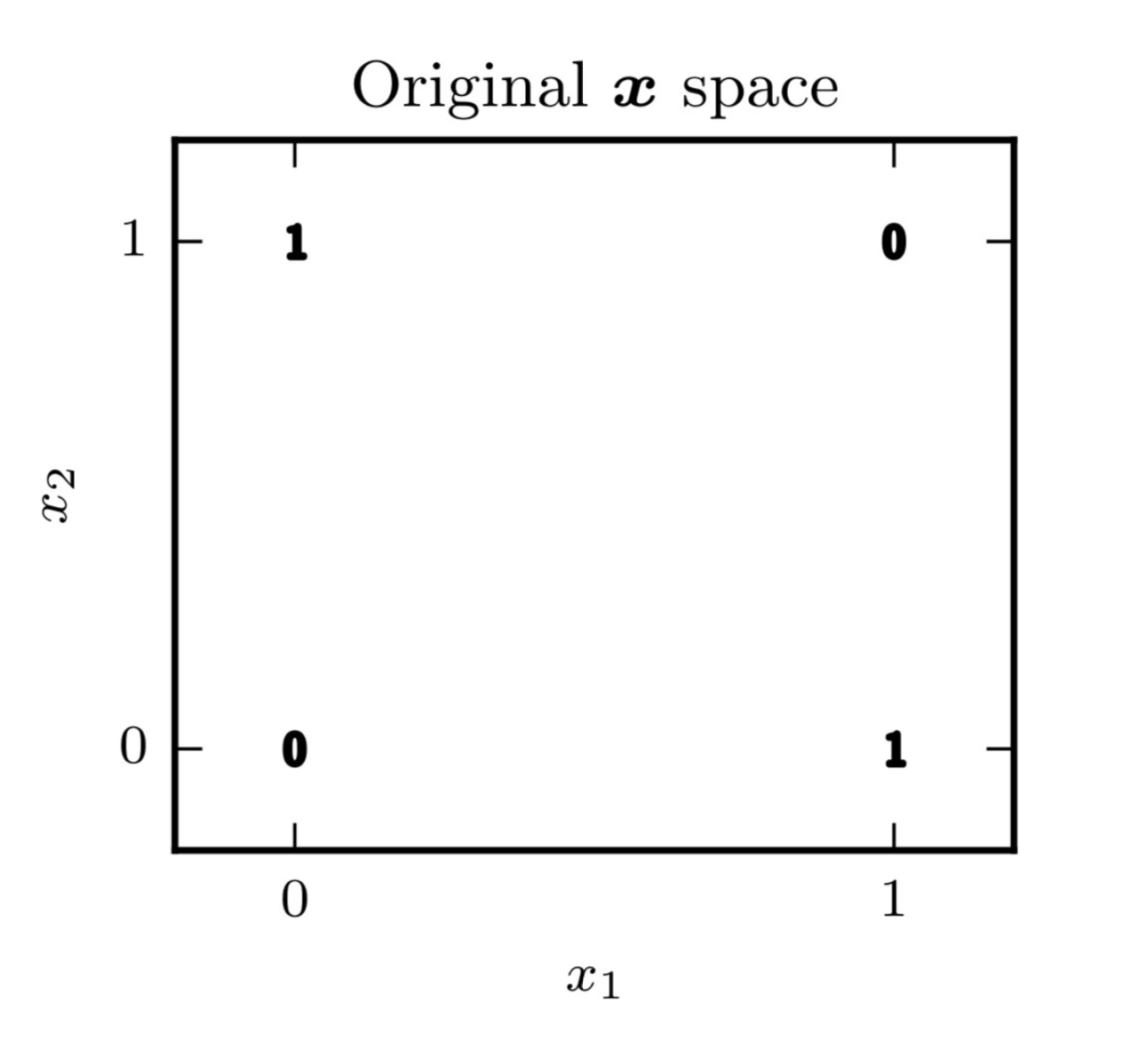
We aim to produce a neural network that is able to classify accurately those four data points (in other words, we will test our classifier on this training data).
The neural network we will use contains one hidden layer with 2 nodes:
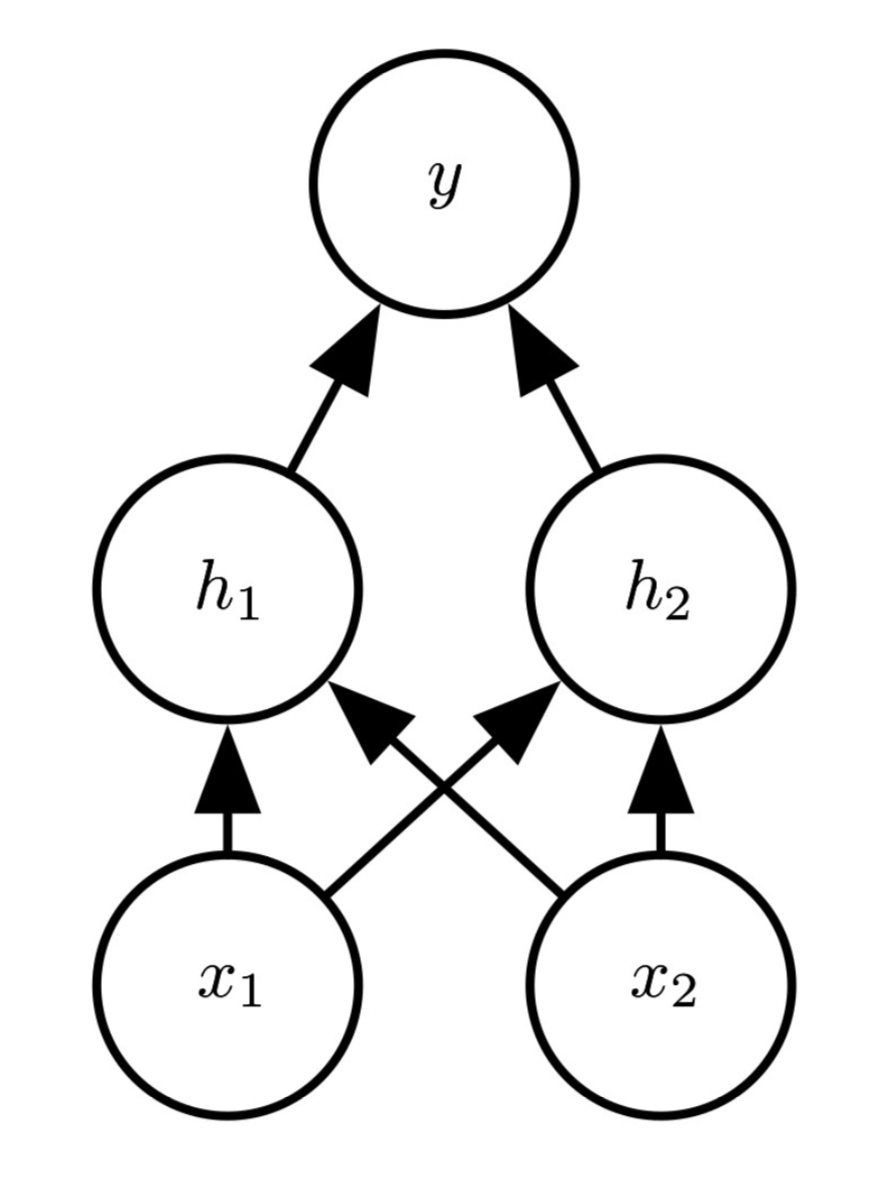
The parameters of our hidden layer are described by the weight matrix and the bias vector:
For the output layer, we have the weight vector \(\mathbf{w}_{\mathbf{h} \rightarrow y} = \left[\begin{matrix} w_{h_1 \rightarrow y} \\ w_{h_2 \rightarrow y} \end{matrix}\right]\) and the bias \(b_y\).
The non-linear activation function of the hidden layer is a ReLU, while the output layer includes a sigmoid function. Throughout this task, we will use a learning rate \(\eta = 0.4\) and no regularization (\(\lambda = 0\)).