 INGInious
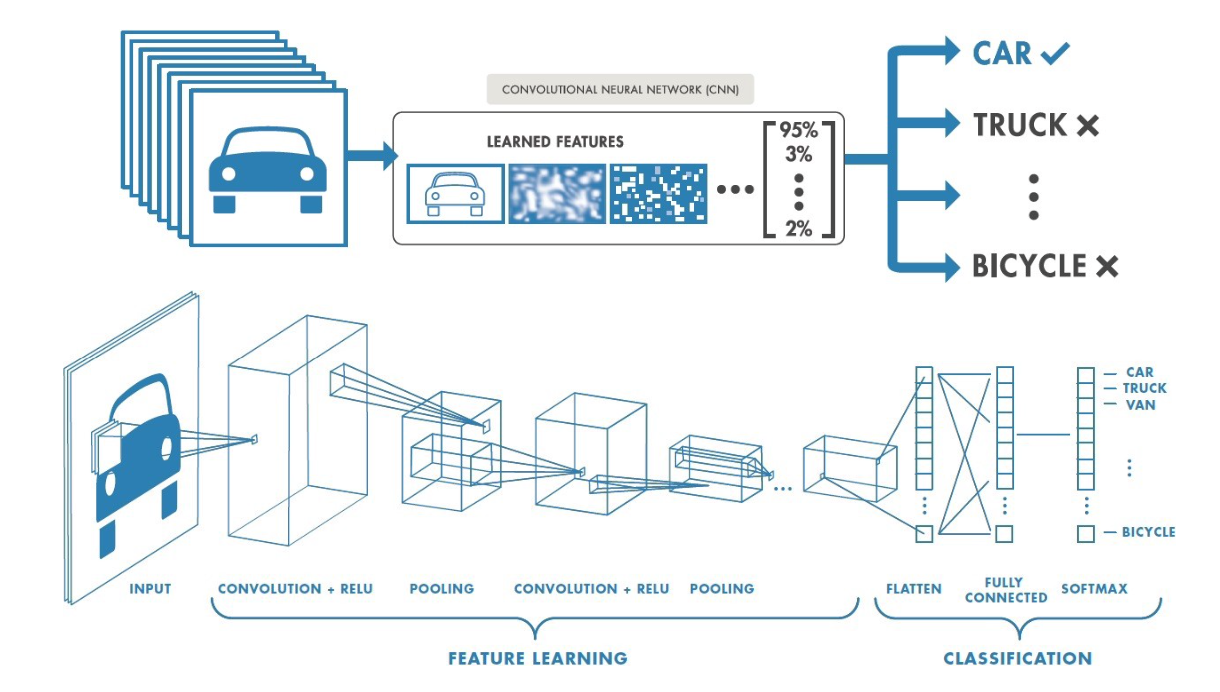
INGIniousWith the traditional neural networks used in the previous tasks, the image, i.e. \(3\) 2D-matrices of pixels (one matrix for each color channel), has been flattened into a 1D vector in the very first layer. By doing this, we loose a lot of spatial information... This is where Convolutional Neural Networks come in!
CNNs are inspired from the neural architecture of the visual cortex, and have therefore proven to be particularily effective for many image recognition tasks. Individual neurons receive information from a restricted region of the image, and the network is designed such that the filter positions overlap to cover the entire picture. Using this principle, features of the image are learned before flattening the information in a vector. This vector is then used for classification using dense layers like you experimented in the previous tasks.
You can load the data with the following code snippet. Note that the order of the channels is changed (as compared to the previous task) to fit the expected input of Keras Conv2D layers.
x_train = np.load("p4_2026_svhn_train.npz")["images"].transpose(3, 0, 1, 2)
y_train = np.load("p4_2026_svhn_train.npz")["labels"].squeeze()
x_test = np.load("p4_2026_svhn_test.npz")["images"].transpose(3, 0, 1, 2)
y_test = np.load("p4_2026_svhn_test.npz")["labels"].squeeze()
# Convert string labels as int, followed by one-hot encoding
labels = sorted(list(set(y_train)))
y_train = keras.utils.to_categorical([labels.index(x) for x in y_train])
y_test = keras.utils.to_categorical([labels.index(x) for x in y_test])